NVIDIA Reference Architecture
Nexus infrastructure is designed around NVIDIA-certified stacks — including GB200, MGX, and H100 systems — optimized for scalable AI training, inference, and sovereign cloud workloads.
All Nexus deployments follow NVIDIA-validated reference architecture — built around modular Scalable Units (SUs) to ensure consistency, performance, and compatibility across global sites. Each SU integrates liquid-cooled high-density racks, GPU clusters, and NVIDIA system architecture optimized for LLMs and foundation model workloads.
Each deployment uses modular Scalable Units (SUs), enabling high-performance clusters optimized for AI training, inference, and large-scale data processing. This modular approach allows for predictable scaling across geographies while maintaining consistent performance characteristics.
Technical Backbone
Built on NVLink5 + NVSwitch
High-bandwidth, low-latency connections between GPUs for maximum performance in distributed training
UFM & Base Command integration
Unified Fabric Manager and NVIDIA Base Command for comprehensive cluster management and monitoring
BlueField-3 DPUs
Data Processing Units offload networking, security, and storage tasks from CPUs for improved performance
Liquid-cooled MGX standards
Compliant with NVIDIA's Modular GPU Express (MGX) standards for liquid-cooled rack deployments
Scalable Unit Design
SU-based cluster scaling
Modular Scalable Units (SUs) enable predictable performance and consistent deployment across geographies
Pre-validated for NVIDIA workload orchestration
Each SU is pre-validated for NVIDIA workload orchestration tools and integrates directly into sovereign AI environments
InfiniBand and Spectrum-X switching fabrics
Support for high-performance networking fabrics for maximum throughput and minimal latency
Comprehensive testing
Every cluster is tested using NVIDIA's Base Command and UFM prior to handover
NVIDIA-CERTIFIED STACK
Modular Scalable Units (SUs) for predictable performance
Rear-door heat exchangers with Vertiv chilled water systems
Block-redundant electrical topology with Li-ion UPS (5 min EOL)
N+1 chillers with continuous cooling backup
BMS integration, access control, fire suppression, and CCTV
This alignment with NVIDIA infrastructure standards allows Nexus to deploy faster, maintain workload consistency across regions, and deliver enterprise-grade GPU hosting from Day 1.
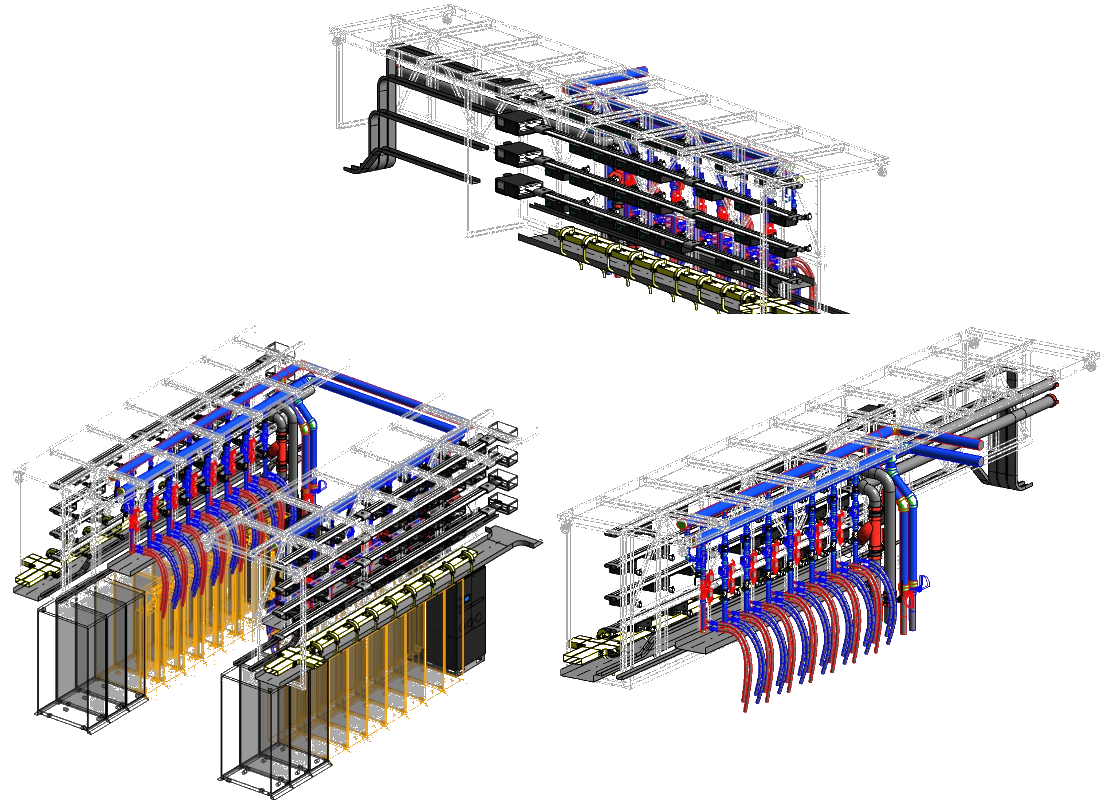
Modular rack infrastructure supporting GB200 and MGX deployments across Nexus sovereign sites.
Supported GPU Architectures
NVIDIA GB200
Blackwell architecture with Grace CPU and B200 Tensor Core GPUs for next-generation AI training and inference.
NVIDIA HGX H100/H200
Hopper architecture with NVLink and NVSwitch for high-performance computing and AI workloads.
NVIDIA MGX GH200
Grace Hopper Superchip with integrated CPU and GPU for accelerated computing in a compact form factor.
Ready for NVIDIA-powered AI infrastructure?
Contact our team to learn how our NVIDIA reference architecture can accelerate your AI initiatives.